


Advancements in machine learning and speech recognition technology have made information more accessible to people, particularly those who rely on voice to access information. However, the lack of labelled data for numerous languages poses a significant challenge in developing high-quality machine-learning models.
In response to this problem, the Meta-led Massively Multilingual Speech (MMS) project has made remarkable strides in expanding language coverage and improving the performance of speech recognition and synthesis models.
By combining self-supervised learning techniques with a diverse dataset of religious readings, the MMS project has achieved impressive results in growing the ~100 languages supported by existing speech recognition models to over 1,100 languages.
Breaking down language barriers
To address the scarcity of labelled data for most languages, the MMS project utilised religious texts, such as the Bible, which have been translated into numerous languages.
These translations provided publicly available audio recordings of people reading the texts, enabling the creation of a dataset comprising readings of the New Testament in over 1,100 languages.
By including unlabeled recordings of other religious readings, the project expanded language coverage to recognise over 4,000 languages.
Despite the dataset’s specific domain and predominantly male speakers, the models performed equally well for male and female voices. Meta also says it did not introduce any religious bias.
Overcoming challenges through self-supervised learning
Training conventional supervised speech recognition models with just 32 hours of data per language is inadequate.
To overcome this limitation, the MMS project leveraged the benefits of the wav2vec 2.0 self-supervised speech representation learning technique.
By training self-supervised models on approximately 500,000 hours of speech data across 1,400 languages, the project significantly reduced the reliance on labelled data.
The resulting models were then fine-tuned for specific speech tasks, such as multilingual speech recognition and language identification.
Impressive results
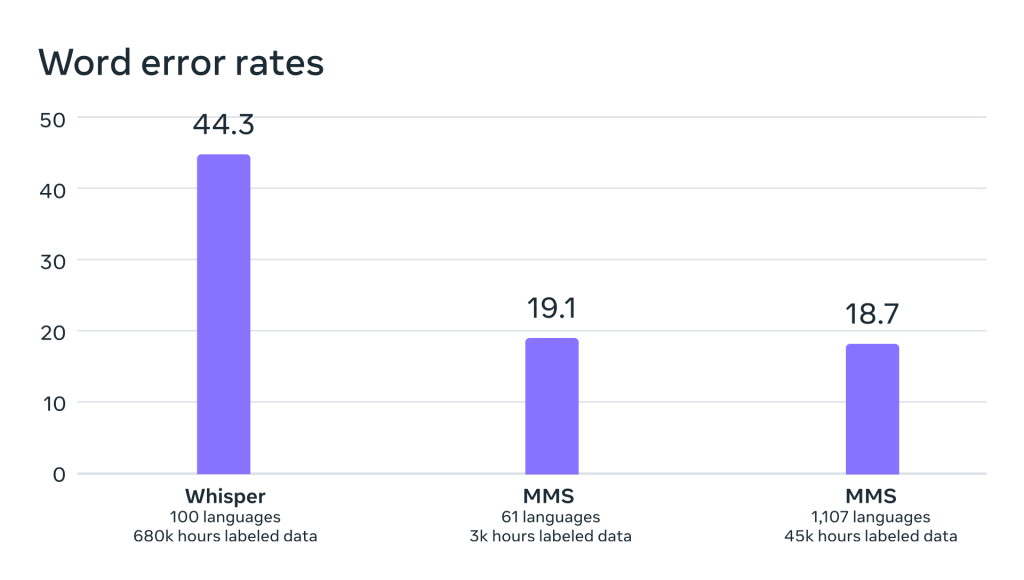
Evaluation of the models trained on the MMS data revealed impressive results. In a comparison with OpenAI’s Whisper, the MMS models exhibited half the word error rate while covering 11 times more languages.
Furthermore, the MMS project successfully built text-to-speech systems for over 1,100 languages. Despite the limitation of having relatively few different speakers for many languages, the speech generated by these systems exhibited high quality.
While the MMS models have shown promising results, it is essential to acknowledge their imperfections. Mistranscriptions or misinterpretations by the speech-to-text model could result in offensive or inaccurate language. The MMS project emphasises collaboration across the AI community to mitigate such risks.
You can read the MMS paper here or find the project on GitHub.

Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The event is co-located with Digital Transformation Week.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.




