


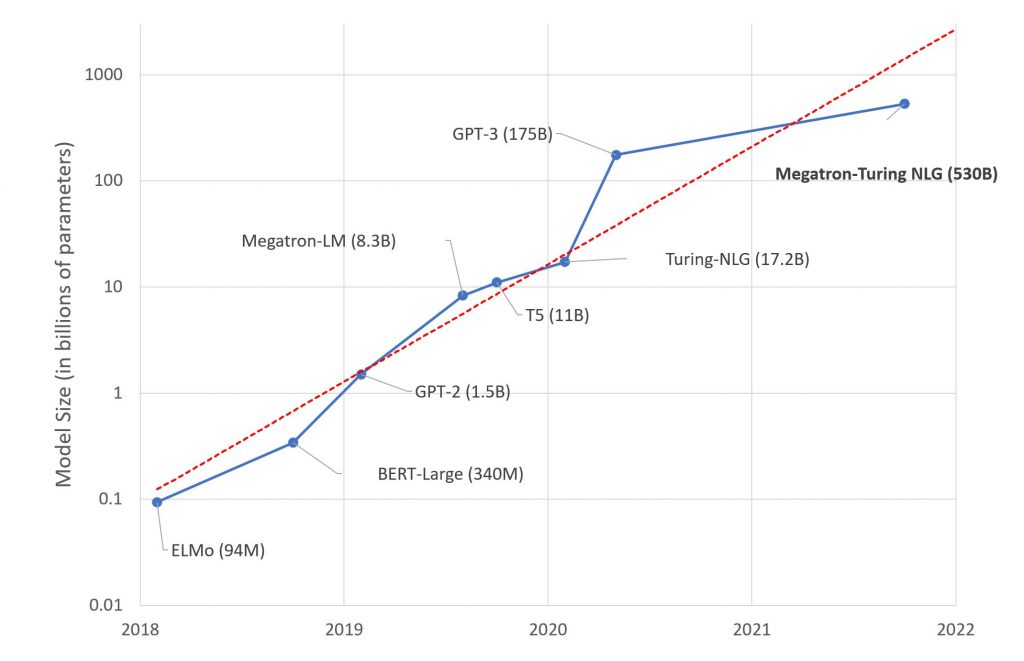
Nvidia and Microsoft have developed an incredible 530 billion parameter AI model, but it still suffers from bias.
The pair claim their Megatron-Turing Natural Language Generation (MT-NLG) model is the “most powerful monolithic transformer language model trained to date”.
For comparison, OpenAI’s much-lauded GPT-3 has 175 billion parameters.
The duo trained their impressive model on 15 datasets with a total of 339 billion tokens. Various sampling weights were given to each dataset to emphasise those of a higher-quality.
The OpenWebText2 dataset – consisting of 14.8 billion tokens – was given the highest sampling weight of 19.3 percent. This was followed by CC-2021-04 – consisting of 82.6 billion tokens, the largest amount of all the datasets – with a weight of 15.7 percent. Rounding out the top three is Books 3 – a dataset with 25.7 billion tokens – that was given a weight of 14.3 percent.
However, despite the large increase in parameters, MT-NLG suffered from the same issues as its predecessors.
“While giant language models are advancing the state of the art on language generation, they also suffer from issues such as bias and toxicity,” the companies explained.
“Our observations with MT-NLG are that the model picks up stereotypes and biases from the data on which it is trained.”
Nvidia and Microsoft say they remain committed to addressing this problem.
Find out more about Digital Transformation Week North America, taking place on 9-10 November 2021, a virtual event and conference exploring advanced DTX strategies for a ‘digital everything’ world.




